We made inference time compute scaling more efficient, and used it to make LLMs more accurate.
Efficiency: Parallel Reasoning Chain Pruning
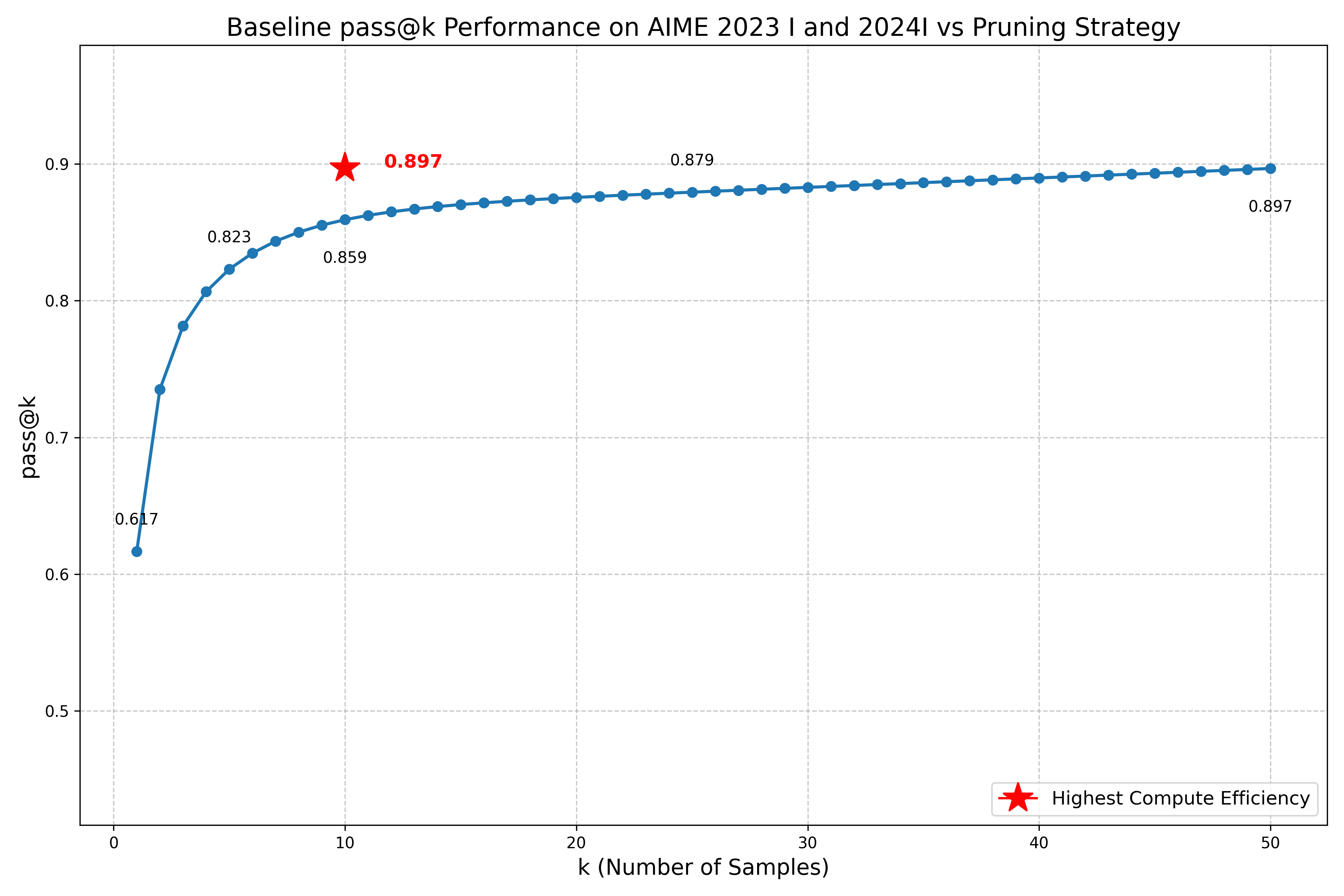
By evaluating the semantic similarity between reasoning chains at various stages and pruning similar paths early on in the decoding process, we can achieve the same accuracy as sampling 50 approaches while only decoding 10 to completion
Accuracy: Inference-Time Hallucination Detection via Self-Verification
By having reasoning LLMs extend their thinking with self-verification statements after reaching an answer, we can implement a majority-vote mechanism to detect hallucinations, enabling confidence-based compute allocation for improved accuracy on various benchmarks.
Parallel Reasoning Chain Pruning
Our research demonstrates that parallel reasoning chain pruning can achieve the same accuracy as sampling 50 approaches while pruning 80% of the reasoning chains at only 300 tokens decoded.
As reasoning LLMs grow more and more popular for use in production coding and mathematics - domains with strong verifiers - we believe that decoding many reasoning chains in parallel for a prompt will become a common practice to scale inference time compute and improve performance.
However, these reasoning chains can go on for tens of thousands of tokens, and take up valuable bandwidth during inference (in both GPUs and custom ASICS like Sohu). Instead of decoding reasoning chains that we can predict will be redundant, we can prune them early on in the decoding process via the methdology we describe.
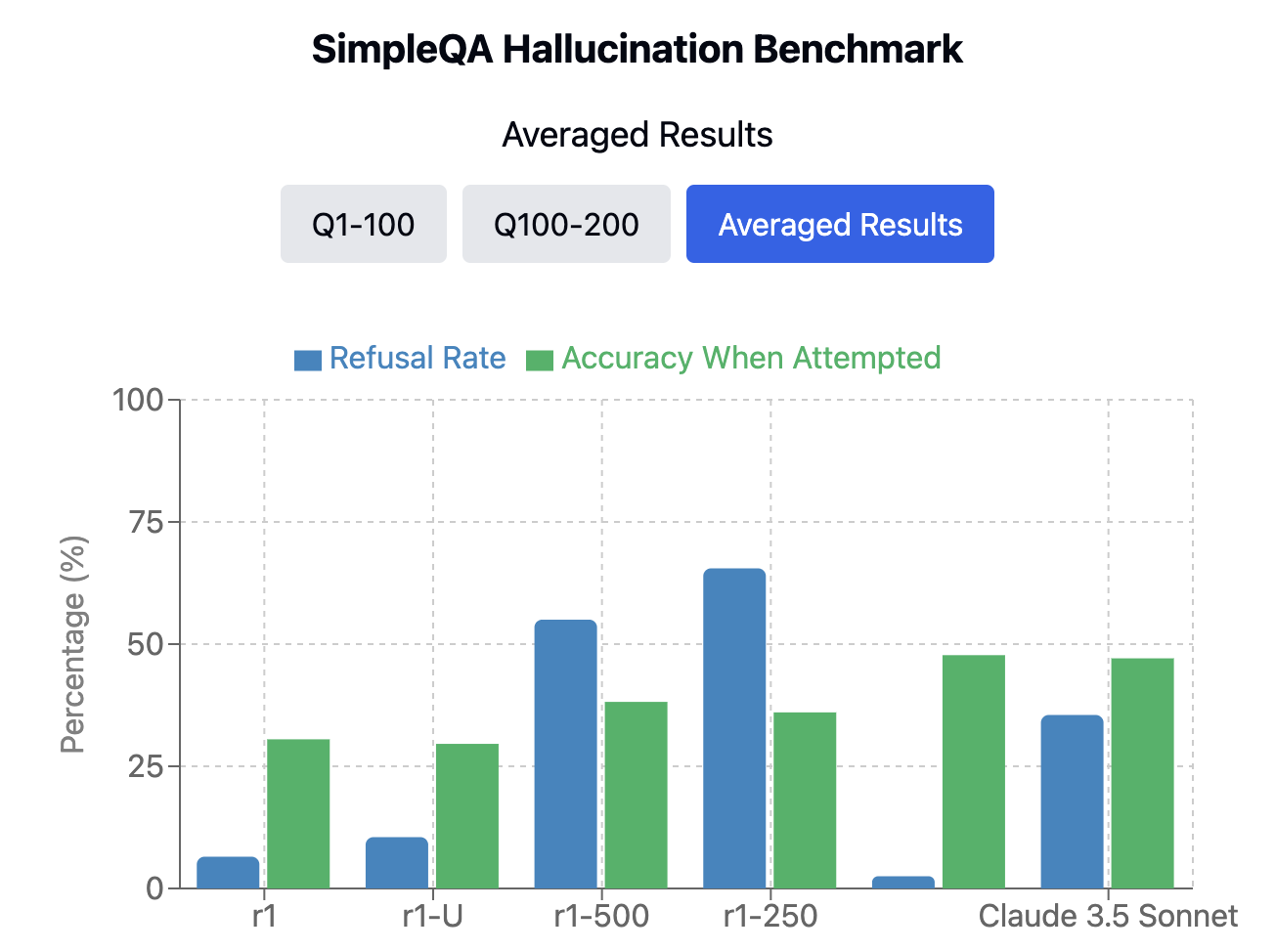
Inference-Time Hallucination Detection via Self-Verification
We discovered that by allowing reasoning models to self correct their answers to hallucination benchmarks and analyzing the diversity of their reasoning as a hueristic for model confidence, we can detect model hallucations at a higher rate and offer refusals instead of a confidently incorrect answer
This allows us to offer a confidence-based compute allocation mechanism that can offer a model that is capable of knowing when its wrong instead of outputing something misleading.
We prove this out on the SimpleQA benchmark, where our method shows a marked improvement in providing refusals instead of confidently incorrect answers.
Tangible Applications
Our optimal test-time computation research potentially addresses critical challenges in AI deployment.
We're out of GPUs
As AI capabilities expand, we're facing unprecedented demand for compute. Our research could offer optimizations that help alleviate this bottleneck.
"...we will add tens of thousands of GPUs next week and roll it out to the plus tier then. (hundreds of thousands coming soon, and i'm pretty sure y'all will use every one we can rack up.)..."
Industry Applications
Our research enables breakthrough capabilities for leading AI innovators:
Etched → Sohu
Sohu, the world's first specialized chip (ASIC) for transformers, could leverage our "parallel reasoning chain pruning" to maximize throughput. By "pruning", Sohu can cut redudant reasoning chains early on, and fill the remaining bandwidth with more user requests, without sacrificing on quality.
Cognition (Devin)
Devin, the AI software engineer, requires high factual accuracy and efficient resource usage when working across large codebases, while not generating any errors. Our refusal research could enable more reliable code generation, making autonomous coding systems like Devin more powerful.
Mercor
For AI-driven development platforms like Mercor, our refusal research could enhance the accuracy of technical solutions while maintaining responsiveness, while our "pruning research" could enable more efficient inference time scaling for their matching agents.
Explore Our Complete Findings
Dive deeper into our research with these comprehensive resources.
Parallel Reasoning Chain Pruning
Encouraging efficiency in inference-time compute by pruning redundant reasoning chains early on.
Read the full paper →Hallucination Detection
Detecting and rejecting hallucinations at inference time with diversity-based analyses of parallel reasoning chains.
Read the full paper →About Our Team
We like AI. We love trying to make it better.



Get in Touch
Interested in learning more about our research or exploring collaboration opportunities? Reach out to us at our LinkedIn profiles!