Benchmark: SimpleQA
We utilize OpenAI's SimpleQA, a benchmark for measuring language model factuality, featuring 4,326 diverse fact-seeking questions with verified answers, where model responses are classified as "correct," "incorrect," or "not attempted" using a prompted classifier, specifically designed to identify and reduce hallucinations in AI-generated content.
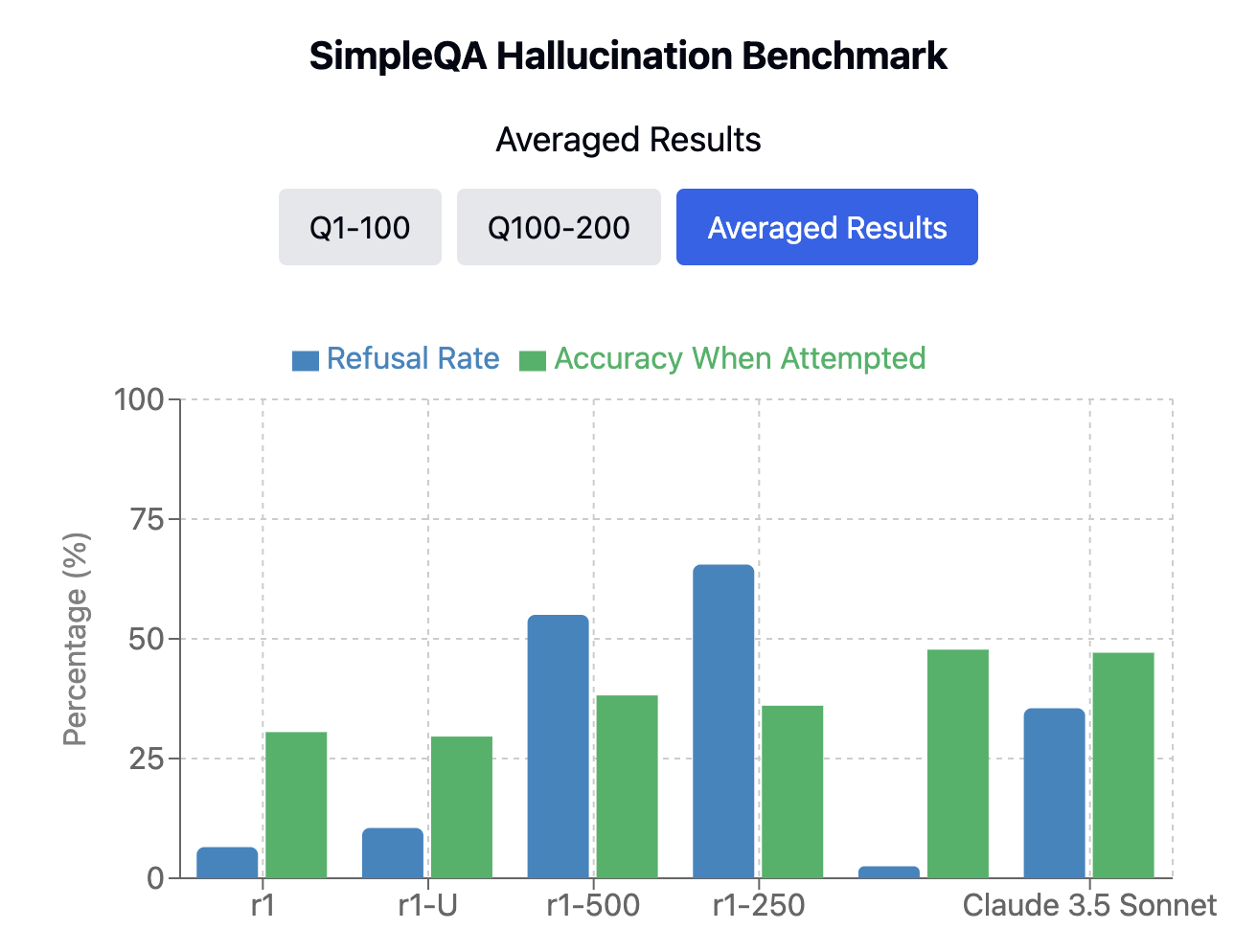
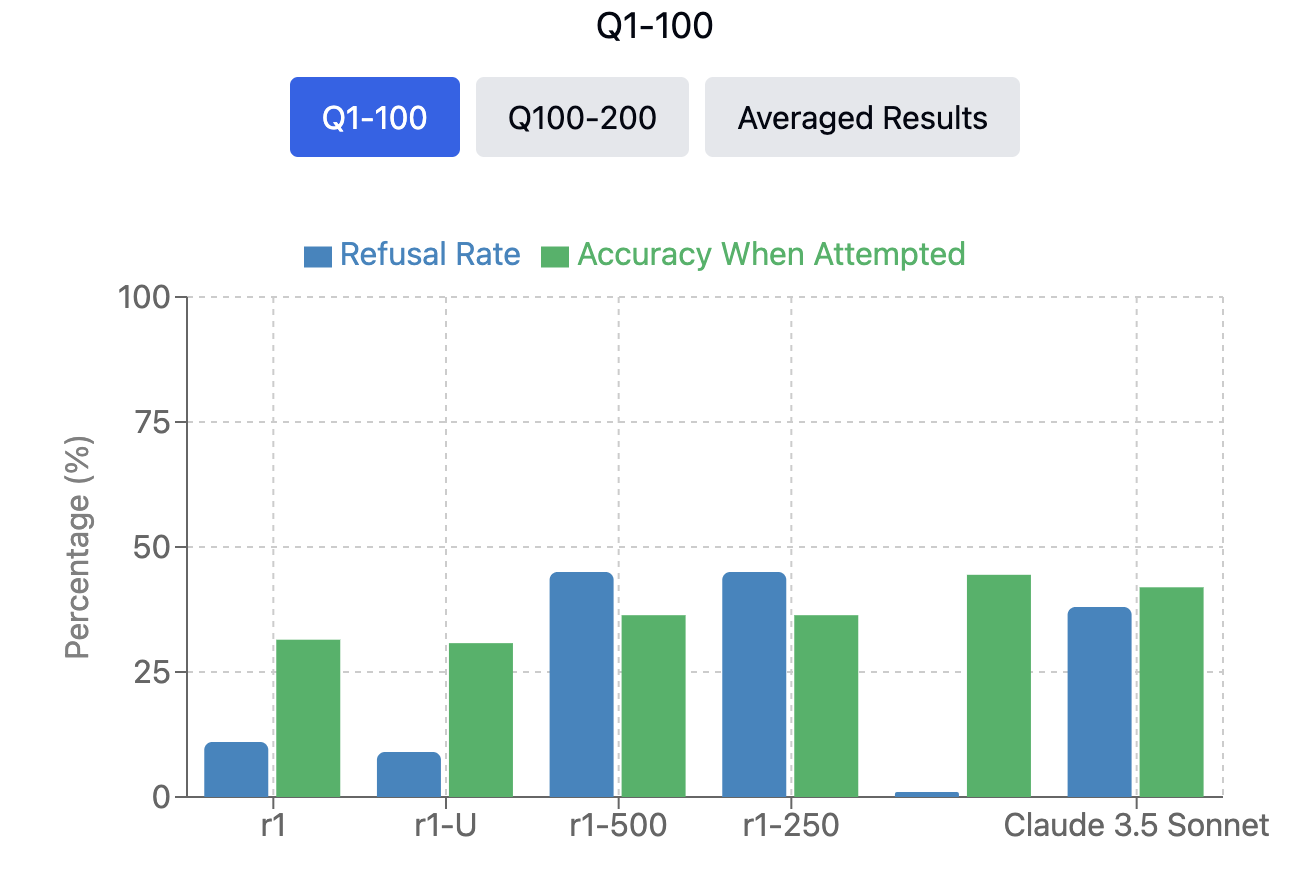
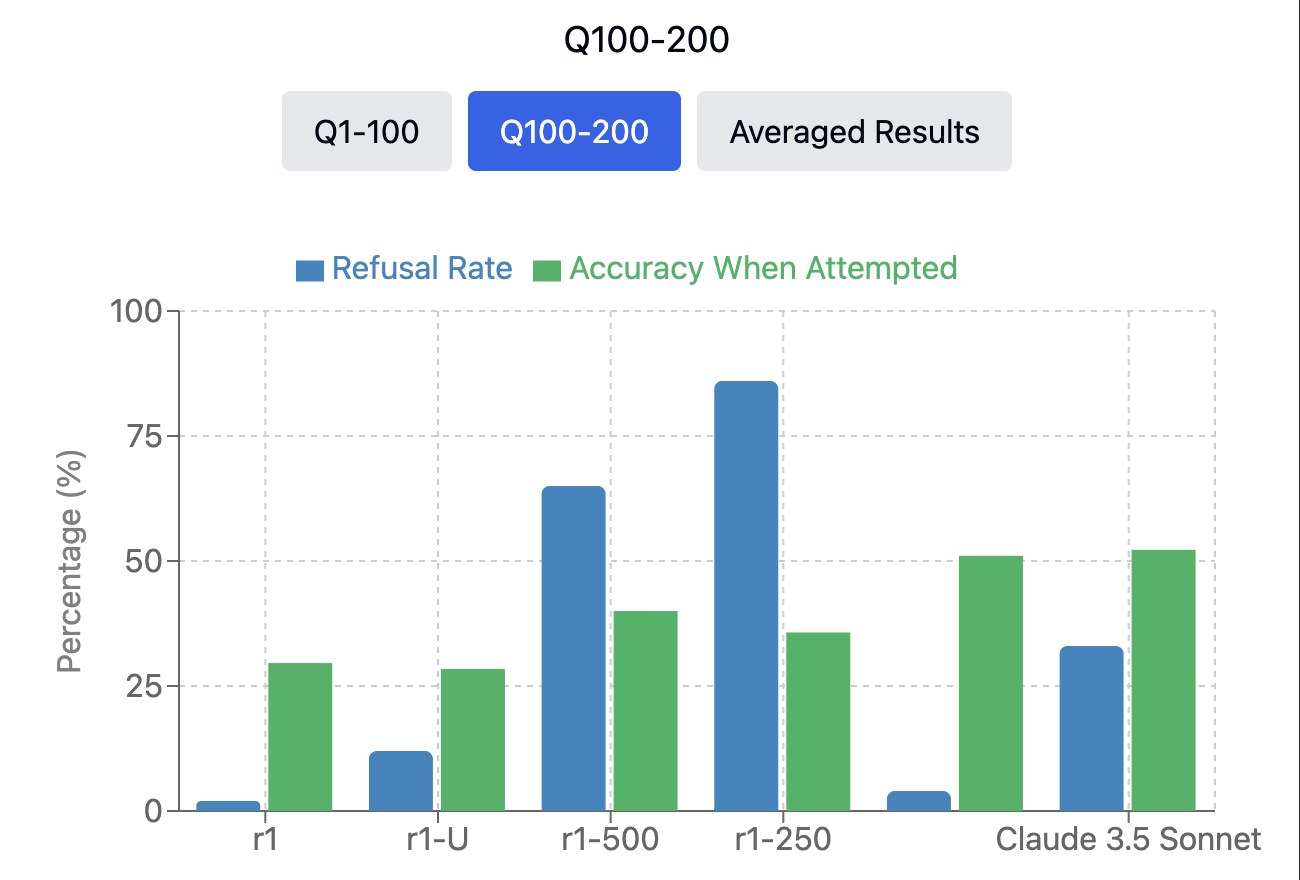
Given budget and compute constraints, we form two sets, the first 100 and second 100 questions of SimpleQA to evaluate on, and report results for both.
Model: Deepseek R1
We utilize Deepseek R1 for this because of its open-source reasoning traces and reported ability to self-correct, as well as the ability to insert prefills into its thinking tokens, crucial to our method. For this paper, all results are from the full 671B version of Deepseek R1. We run Deepseek R1 using the Fireworks API, with a temperature of 1.0 and a top p of 1.
Answer Diversity through SLMs
An initial attempt we tried, for finding consensus from parallel reasoning chains (the original motivation for this work) was to simply measure the answer diversity after the reasoning chains had concluded (and the answer was extracted from the response after the </think> token). We discovered that the reasoning model often arrived at the same conclusion, with fairly different reasoning chains or rationales. Thus, this did not work on our preliminary experiments.
Because we ultimately did not follow through with this method, we do not include its results in the Results Section.
Continuation Diversity through Embeddings
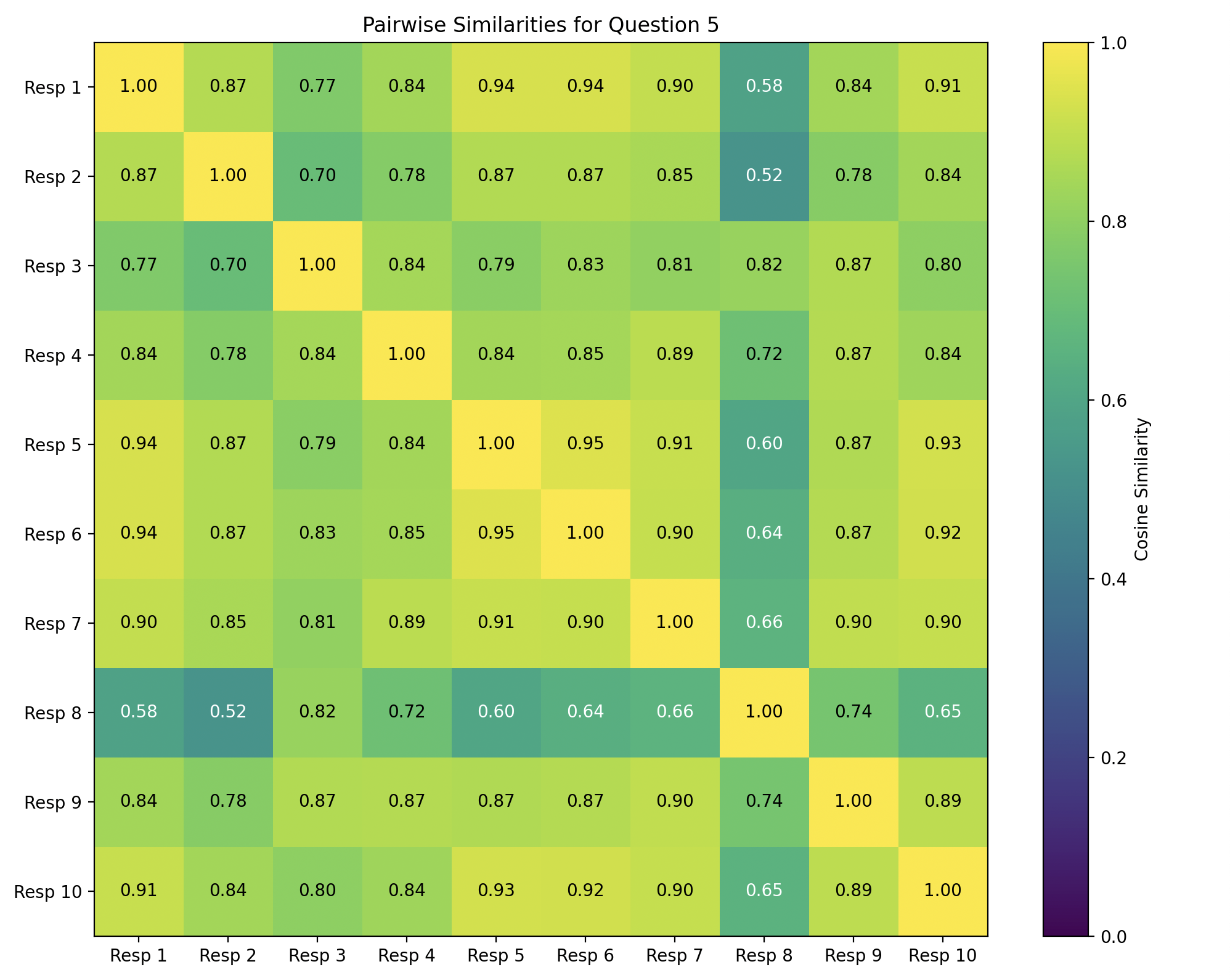
The next intuition we had was that if many different reasoning chains were being used to arrive to the same conclusion, then that conclusion could likely be false. Or in the rare case, supported by many different sources and thus true. Our first attempt at measuring reasoning chain diversity (solely the sequence starting from the injected interruption token) was to use embeddings, specifically OpenAI's text-embedding-3-small. What we discovered was that similarity rates were often very high, and the embeddings did not capture the nuance we wanted. When comparing 2 large-token chains-of-thought with just 1 or 2 differences, its likely that the embedding cosine similarity (what we used to measure diversity) will be very high even if those changes result in very different reasoning traces.
Because we ultimately did not follow through with this method, we do not include its results in the Results Section. We include details and figures about this in the appendix.
Reasoning Diversity though SLMs
We ultimately decided to use a SLM to judge reasoning chain diversity, using Gemini 2.0 Flash-Lite as a proxy instead of locally hosting a solution, as our compute node was being fully utilized by our other experiments for another project. The SLM is given all of the parallel reasoning chains, and asked to rate their diversity on a scale from 1-10.